[Redis] 데이터 구조와 명령어
by garimoo
데이터 구조
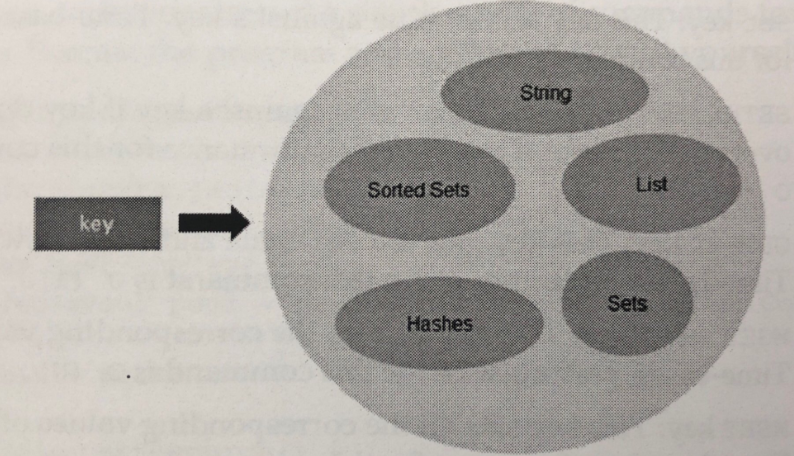
- 지원하는 데이터형
- String
- Hashes
- Sets
- Sorted Sets
- Lists
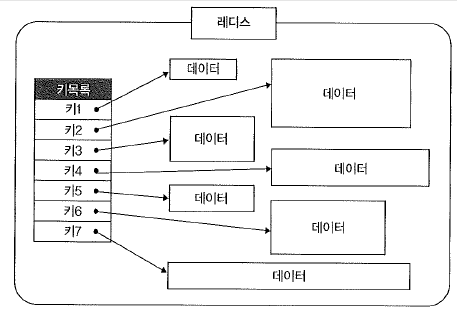
- 논리적 데이터 저장 방식: Map 구조
String
Setters / Getters 명령어
- Get key: key에 해당하는 value 반환
- Set key: key에 value 저장
- SETNX key: key가 없을 때 value 저장. 실패시 0 반환
- GETSET key: 새로운 value 저장, 이전 value 반환. (새로 저장시 nil 반환)
- MGET key1 key: 여러개의 key에 대응하는 value 반환
- MSET key: 여러개의 value 저장
- MSETNX key: 여러개의 value 저장. 이미 존재하는 key가 하나라도 있다면 전체 실패.
Data Clean 명령어
- SET option
SET key value [NX|XX] [EX second] [PX millisecond]- NX: 해당 key가 없는 경우에만 value 저장 (=SETNX)
- XX: 해당 key가 있는 경우에만 value 저장
- EX second: second 이후에 데이터 지워짐 (=SETEX)
- PX millisecond: millisecond 이후에 데이터 지워짐 (=PSETEX)
127.0.0.1:6379> setex key 5 value
OK
127.0.0.1:6379> ttl key
(integer) 2
127.0.0.1:6379> get key
"value"
127.0.0.1:6379> get key
(nil)
Utility 명령어
- APPEND: 기존 value 뒤에 새로운 value 추가. (key가 없는 경우 set과 같음)
- STRLEN: string 길이 반환
- SETRANGE: 주어진 offset에 해당하는 string 을 변환
- GETRANGE: 일부 문자열 조회
- start/end 는 둘다 offset을 의미 (end가 문자열 길이 X)
127.0.0.1:6379> set key1 Hello
OK
127.0.0.1:6379> append key1 Redis
(integer) 10
127.0.0.1:6379> get key1
"HelloRedis"
127.0.0.1:6379> set key "This is MySQL Server"
OK
127.0.0.1:6379> setrange key 8 Redis
(integer) 20
127.0.0.1:6379> get key
"This is Redis Server"
------------------------------------------------------
127.0.0.1:6379> setrange keyy 3 Redis
(integer) 8
127.0.0.1:6379> get keyy
"\x00\x00\x00Redis"
새로운 key에 setrange 명령어를 통해 padding 기능 사용 가능
127.0.0.1:6379> set key "This is Redis Server"
OK
127.0.0.1:6379> getrange key 0 3
"This"
127.0.0.1:6379> getrange key 8 100
"Redis Server"
BitSet / Bitmap 명령어

- SETBIT: 해당 offset에 value 저장
- GETBIT: 해당 offset 위치의 값 반환
- BITCOUNT: value 중 1의 갯수 반환
숫자형 명령어
Getter/Setter, Data Clean 명령어 모두 string 명령어와 같음
- DECR
- DECRBY: 지정한 숫자만큼 감소
- INCR
- INCRBY: 지정한 숫자만큼 증가
- INCRBYFLOAT: 지정한 숫자(정수/유리수) 만큼 증가.
- 감소의 경우 음수 입력 가능
Hashes
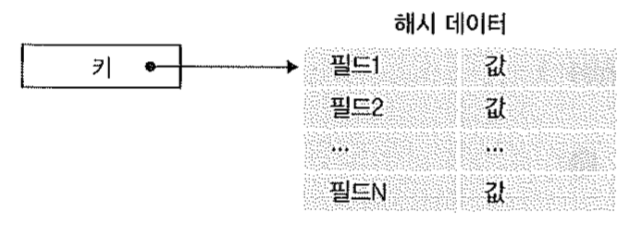
- 키 하나에 여러개의 (field/value) 쌍이 매핑
- key 하나에 field와 value 쌍을 40억개(4,294,967,295)까지 저장 가능
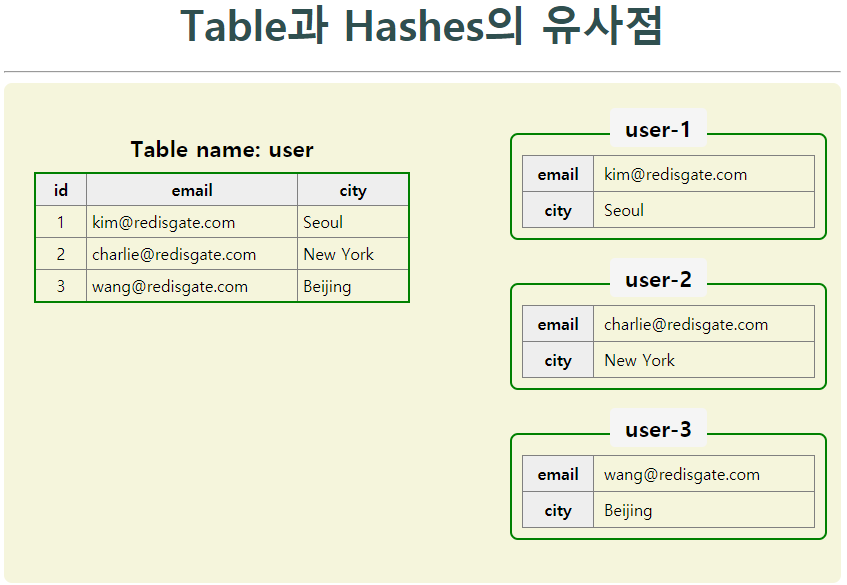
Table / Hash 유사점
- Hashes가 field와 value로 구성된다는 면에서 RDB의 table과 비슷
- Hash key는 table의 PK, field는 column, value는 value로
- Key가 PK와 같은 역할을 하기 때문에 key 하나는 table의 한 row와 같음
Table / Hash 차이점
- Table의 column 수는 일반적으로 제한이 있는 반면, Hash의 field 수는 40억개로 거의 무제한
- Table에서 column을 추가하려면 alter문으로 미리 table을 변경해야 하나, Hash에서는 자유로운 field의 추가/삭제
- Field의 추가/삭제는 해당 key에만 영향을 미침
Setters / Getters 명령어
- HGET: key, field로 value 조회
- HGETALL: key에 속한 모든 field와 value를 조회
- HSET: key에 여러개의 field와 value를 저장 가능. 기존에 같은 field가 있으면 덮어씀.
- HMGET: 여러개의 value 조회
- HMSET : 버전 4.0.0부터는 hmset 대신 hset을 사용할 것을 권장
- HVALS: key에 속한 모든 value를 조회
- HSETNX: field가 기존에 없으면 저장. 있으면 실패(-1)
- HKEYS: key에 속한 모든 field name을 조회
Data Clean 명령어
- HDEL: 지정한 field와 value를 삭제한다. field를 여러개 지정 가능
Utility 명령어
- HEXISTS: field가 있는지 조회. 있으면 1, 없으면 0 반환
- HINCRBY: value를 increment 만큼 증가 또는 감소. 해당 field가 없으면 increment 값을 set.
- HINCRBYFLOAT
- HLEN: field의 개수 조회
Lists
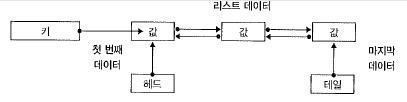 key와 value가 일 대 다 관계
key와 value가 일 대 다 관계
Setters / Getters 명령어
- LPUSH: 리스트의 왼쪽에 데이터를 저장
- LPUSHX: 키가 이미 있을 경우에만 리스트의 왼쪽에 데이터를 저장
- RPUSHX: 키가 이미 있을 경우에만 리스트의 오른쪽에 데이터를 저장
- LINSERT: 값으로 특정 위치에 데이터 넣기
linsert key BEFORE | AFTER pivot value- 기준이 되는 데이터(pivot)을 기준으로 전.후에 value를 넣는다.
- 예시
- LSET: index의 위치에 있는 데이터를 새로운 데이터로 변환
lset key index value
- LRANGE: 인덱스로 범위를 지정해서 리스트 조회
Data Clean 명령어
- LTRIM: 인덱스로 지정한 범위 밖의 데이터를 삭제. 지정한 범위의 데이터만 남기고 나머지를 모두 삭제시 유용.
- RPOP: 리스트 오른쪽에서 데이터를 꺼내옴.
- LREM:
- LPOP: 리스트 왼쪽에서 데이터를 꺼내옴
Utility 명령어
- LINDEX: 인덱스로 특정 위치의 데이터를 조회
- index를 왼쪽부터 지정할때는 (0, 1, 2), 오른쪽 부터 지정할때는 (-1, -2, -3) 순으로
- LLEN: 리스트에서 value의 개수를 조회
Advanced 명령어
- BLPOP
- BRPOP
- RPOPLPUSH: 리스트 오른쪽에서 데이터를 꺼내서 왼쪽에 넣음.
Sets
- Value는 입력된 순서와 상관없이 저장되며, 중복되지 않음.
- value를 member라 부름 (집합의 의미여서)
Setters / Getters 명령어
- SADD: 집합에 데이터를 추가. 여러개 지정 가능
Data Clean 명령어
- SPOP: random member 1개 삭제
- SREM: 해당 member를 삭제. 여러개 삭제 가능.
Utility 명령어
- SCARD: 집합에 속한 member의 개수를 조회
- SISMEMBER: 집합에 member 존재하는지 확인
- SMOVE: 한 집합의 member를 다른 집합으로 이동.
smove source_key destination_key member- source key의 member에서는 지워진다.
- SRANDOMMEMBER: 랜덤 멤버 조회
- SDIFF: 첫번째 집합에서 나머지 집합에 있는 member들을 제거 (차집합)
- SDIFFSTORE: 차집합을 구해서 새로운 집합에 저장
sdiffstore destination_key source_key1 source_key2
- SINTER: 교집합
- SINTERSTORE: 교집합을 구해서 새로운 집합에 저장
- SUNION: 합집합
- SUNIONSTORE: 합집합을 구해서 새로운 집합에 저장
Sorted Sets (ZSets)
- Value는 score로 sort되며, 중복되지 않음.
- score가 같으면 value로 sort (알파벳순)
- 정렬이 필요한 곳에서 사용
Setters / Getters 명령어
- ZADD: score와 함께 member 저장
zadd key score member
- ZRANGE: score 오름차순으로 member list 조회
- withscores 옵션을 사용하면 score 표시됨
- ZRANGEBYSCORE: score로 범위를 지정해서 조회
- ZREVRANGEBYSCORE
- ZRANK: member값을 입력하고 index 반환
- ZREVRANK
- ZREVRANGE
Data Clean 명령어
- ZREM: member 삭제
- ZREMRANGEBYRANK: index 범위로 member를 삭제
zremrangebyrank key start stop- 예시9
- ZREMRANGEBYSCORE: score로 범위를 지정해서 member 삭제
zremrangebyscore key min max- 모두 삭제하려면 -inf, +inf를 사용
- min, max 값을 제외하려면 앞에 ‘(‘ 를 사용
- 예시10
Utility 명령어
- ZCARD: 집합에 속한 member 개수를 리턴
- ZSCORE: member의 score를 리턴
- ZCOUNT: score로 범위를 지정해서 개수 조회
zcount key min max- 예시11
- ZINCRBY: score 증가, 감소
zincrby key increment member- 예시12
- ZINTERSTORE: 교집합을 구해서 새로운 집합에 저장
- ZUNIONSTORE
New Feature
- ZPOPMIN: 작은 값부터 출력
zpopmin key [count]- 기본 count는 1
- ZPOPMAX
- BZPOPMIN: 데이터가 들어오면 작은 값부터 출력
bzpopmin key [key ...] timeout
- BZPOPMAX
KEY 관리
조회 명령어
- KEYS: keys+pattern *
- : 모든 문자 매치
- ?: 1개 문자 매치
- EXISTS: 키가 존재하는지 확인
- SCAN: Key들을 일정 단위 개수 만큼씩 조회
SCAN cursor [MATCH pattern] [COUNT count]
- SORT: 데이터를 sort 하여 조회
삭제/변경 명령어
- RENAME: key 이름 변경.
- new_key가 이미 존재하면 삭제됨.
- RENAMENX: new_key가 존재하지 않을 경우에만 key 이름을 변경
만료 처리 명령어
- EXPIRE: 지정된 시간(초) 후 key 자동 삭제
- TTL: 남은 expire time(seconds)을 조회
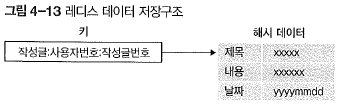
KEY 설계
- RDB
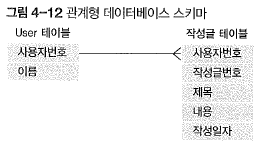
- REDIS
참고 문서
Subscribe via RSS