[STUDY] 오라클 성능 고도화 원리와 해법2 - 01장 인덱스 원리와 활용
by garimoo
[Chapter 1] 인덱스 원리와 활용
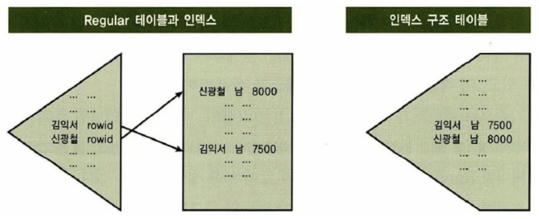
인덱스 구조
범위 스캔
- 인덱스는 key 순으로 정렬되어 있어서 range scan이 가능
- IOT를 제외하면 일반적인 테이블(heap 구조)에서는 불가
인덱스 기본 구조
- B*Tree 구조
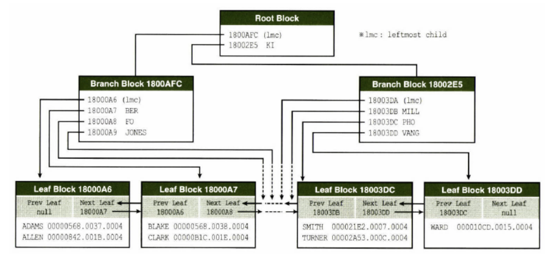
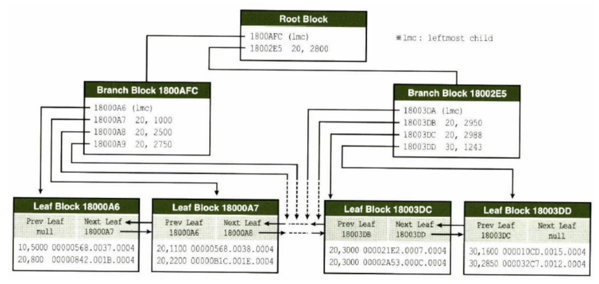
- branch block은 DBA(Data Block Access) 정보를, leaf block은 key column, rowid 를 갖음
- lmc(left most child): 각 브랜치 노드의 첫 번째 엔트리. 키 값을 가진 첫 번째 엔트리보다 작은 값을 의미.
- 테이블 값이 갱신되면 리프노드 인덱스 키 값도 같이 갱신. 브랜치 노드까지 바뀌지는 않음.
- 브랜치 노드는 인덱스 분할에 의해 새로운 블록이 추가되거나 삭제될 때만 갱신.
인덱스 탐색
- 수직적 탐색: range scan. 수평적 탐색을 위한 시작점을 찾는 과정.
- 수평적 탐색: leaf blokc을 좌, 우로 스캔.
- 브랜치 블록 탐색
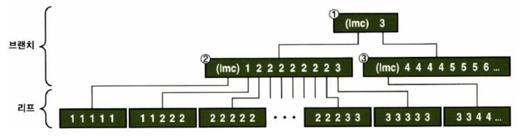
- 탐색은 뒤에서부터 스캔하고, 찾고자 하는 값보다 키가 작은 엔트리를 따라 내려가야 함.
- 결합 인덱스 구조
ROWID 포맷
- data file 번호, block 번호, row 번호같은 테이블 레코드의 물리적 위치정보를 포함.
- 테이블 레코드를 찾아가는데 필요하므로 index에 저장. 테이블에는 저장되어있지 않는 pseudo column
- 데이터 블록 헤더에 물리적인 정보들(object, datafile 번호 등)이 저장되어 있어서 rowid를 읽을 때 가공 가능
- 크기
- ~ver. 7: 6바이트
- restricted rowid format: 구분자 포함 18자리
- datafile 번호 (4)
- block 번호 (8)
- row 번호 (4)
- restricted rowid format: 구분자 포함 18자리
- ver.8 ~: 10바이트 (하지만 파티션되지 않은 인덱스는 6바이트)
- extended rowid format: 구분자 없이 18자리
- data object 번호 (6)
- datafile 번호 (3)
- block 번호 (6)
- row 번호 (3)
- extended rowid format: 구분자 없이 18자리
- ~ver. 7: 6바이트
인덱스 기본 원리
인덱스 사용이 불가능하거나 범위 스캔이 불가능한 경우
- index full scan은 가능, index range scan이 불가능한 경우
- 인덱스 컬럼을 조건절에서 가공하는 경우
- 부정형 비교: where 직업 <> ‘학생’
- is not null 조건
- index 사용이 불가능한 경우
- is null 조건
- 하지만, not null 조건 column을 is null 조건으로 검색하면 index scan에 가서 공집합을 반환.
- is null 조건
인덱스 컬럼의 가공
컬럼 가공 사례
| 컬럼 가공 | 튜닝 방안 |
|---|---|
| where substr(업체명,1,2) = ‘대한’ | where 업체명 like ‘대한%’ |
| where 월급여 * 12 = 360000 | where 월급여 = 360000/12 |
| where to_char(일시,’yyyymmdd’) = :dt | where 일시 >= to_date(:’dt, ‘yyyymmdd’) and 일시 < to_date (:dt, ‘yyyymmdd’) + 1 |
where 연령 || 직업 = '30공무원' |
where 연령 = 30 and 직업 = ‘공무원’ |
where 회원번호 || 지점번호 =: str |
where 회원번호 = substr(:str,1,2) and 지점번호 = substr(:str,3,4) |
튜닝 사례
- 인덱스 구성
PK: 수신번호 INDEX : 정정대상접수번호 + 금감원접수번호 - 튜닝 전 쿼리
SELECT * FROM 접수정보파일 WHERE decode( 정정대상접수번호, lpad(' ',14), 금감원접수번호, 정정대상접수번호) =: 접수번호 - 튜닝 후 쿼리: decode 조건절 재구성
SELECT * FROM 접수정보파일 WHERE 정정대상접수번호 in (:접수번호, lpad(' ', 14)) and 금감원접수번호 = decode (정정대상접수번호, lpad(' ', 14), :접수번호, 금감원접수번호)
묵시적 형변환
- 숫자형과 문자형이 비교될 때는 숫자형이 우선됨.
- =로 비교하기 전에 to_char를 통해 문자형 비교로 변경
- 성능 문제 뿐 아니라 쿼리 수행 도중 에러 발생 가능.
- 형변환에 의해 숫자로 변환될 때, 변환되지 못하는 문자열이 있을 수 있음.
- decode(a, b, c, d) 함수에서 출력되는 값의 데이터 타입은 c에 의해 결정됨.
- 만약 c가 null이면 varchar2로 출력됨.
- FBI(Function Based Index) 활용: 급한 불을 끌 때 사용.
다양한 인덱스 스캔 방식
Index Range Scan
- 수직적 탐색(root block ~ leaf block) 후 수평 탐색(leaf block)
- 일반적인 액세스 방식
- 실행 계획에
INDEX (RANGE SCAN)
Index Full Scan
- 수직적 탐색 없이 leaf block을 처음부터 끝까지 수평적으로 탐색하는 방식.
- 실제로는 첫 번째 leaf block을 찾기 위해 제일 왼쪽에서 수직적 탐색이 일어남.
- 최적의 인덱스가 없을 때 차선으로 선택됨
- 실행 계획에
INDEX (FULL SCAN) - index scan 단계에서 대부분 레코드의 필터링이 가능하다면 유리. 하지만 index에서 대부분의 레코드가 선택되면 불리.
Index Unique Scan
- 수직탐색으로만 데이터를 찾는 방식. ‘=’조건으로 탐색하는 경우에만 작동
- 한 건의 데이터를 찾는 순간 더이상의 탐색은 없음.
- 실행 계획에 ‘INDEX (UNIQUE SCAN)’
- unique index더라도, ‘>=’ 등의 조건을 사용하면 range scan을 이용.
Index Skip Scan
- 조건절에 빠진 인덱스 선두 컬럼의 distinct value 개수가 적고, 후행 컬럼의 distinct value 개수가 많을 때 유용
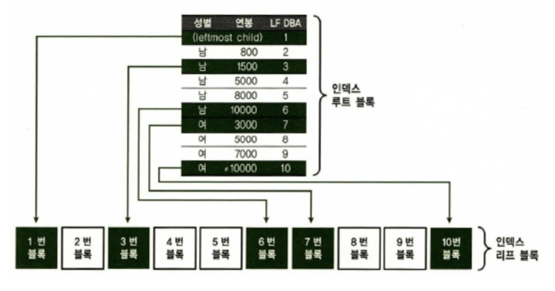
SELECT * FROM 사원 WHERE 연봉 between 2000 and 4000; - Index Skip Scan은 첫 번째 리프 블록을 항상 방문하고, 마지막 리프 블록도 항상 방문.
- 여기에서는 ‘남’보다 작은 성별이나, ‘여’보다 큰 성별 값이 존재하는지 확인해 보기 위해서 방문.
- Index Skip Scan이 작동하기 위한 조건
- 3개 컬럼의 index가 존재할 때, 최선두 컬럼은 입력하고, 중간 컬럼에 대한 조건절이 누락된 경우.
- distinct value 개수가 적은 두 개의 선두컬럼이 모두 누락된 경우
- 선두컬럼이 범위조건일 때
Index Fast Full Scan
- Index Fast Scan보다 빠름. 인덱스 트리구조를 무시하고 인덱스 세그먼트 전체를 multiblock read 방식으로 스캔.
- 인덱스를 읽지만 결과집합 순서 보장 안됨.
- 병렬스캔 가능.
- 인덱스에 포함된 컬럼으로만 조회할 때 사용 가능.
Index Range Scan Descending
- index range scan과 동일한 방식, 내림차순으로 정렬된 결과집합을 얻는다는 것만 다름
And-Equal, Index Combine, Index join
- and-equal: 10g부터 폐기.
- index combine: 데이터 분포도가 좋지 않은 두 개 이상의 인덱스를 결합해 테이블 random 액세스량을 줄이는 데에 목적이 있음.
- b* index를 스캔하면서 각 조건을 만족하는 레코드의 rowid 목록을 얻음
- 이 rowid 목록을 가지고 비트맵인덱스 구조를 만듬
- bit-wize 오퍼레이션 수행
- true인 비트 값들을 rowid로 환산해 최종 방문할 rowid 목록 얻음
- rowid 이용해서 테이블 액세스
- index join: 한 테이블에 속한 여러 인덱스를 이용해 테이블 액세스 없이 결과집합을 만들 때 사용하는 인덱스 스캔 방식
- 쿼리에 사용된 컬럼들이 인덱스에 모두 포함될 때만 작동
테이블 Random 액세스 부하
인덱스 ROWID에 의한 테이블 액세스
TABLE ACCESS (BY INDEX ROWID)- 오라클은 DBA(Data Block Address)를 해시 키 값으로 삼아 해싱 알고리즘을 통해 버퍼 블록을 찾음. 매번 위치가 달라지더라도 (버퍼에서 밀려났다가 다시 캐싱되기 때문에) 캐싱되는 해시 버킷만은 고정적.
- 인덱스 rowid는 테이블 레코드와 물리적으로 연결되어 있지 않기 때문에 인덱스를 통한 테이블 액세스는 고비용구조.
- 모든 데이터가 메모리에 캐싱돼 있더라도 매번 DBA를 해싱하고 래치 획득 과정을 반복해야 하기 때문. buffer lock도 고려.
인덱스 클러스터링 팩터
- 모든 데이터가 메모리에 캐싱돼 있더라도 매번 DBA를 해싱하고 래치 획득 과정을 반복해야 하기 때문. buffer lock도 고려.
- 같은 값을 갖는 데이터가 모여 있는 정도를 의미.
-- object_id로 정렬하면서 테이블 생성
create table t
as
select * from all_objects
where rownum<10000
order by object_id;
-- object_id에 대한 인덱스 생성
create index t_object_id_idx on t(object_id);
-- object_name에 대한 인덱스 생성
create index t_object_name_idx on t(object_name);
-- 통계정보 수집
exec dbms_stats.gather_table_stats(user,'T');
-- 클러스터링 팩터 출력
select i.index_name, t.blocks table_blocks, i.num_rows, i.clustering_factor
from user_tables t, user_indexes i
where t.table_name = 'T'
and i.table_name = t.table_name;
 clustering_factor 수치가 테이블 블록에 가까울수록 데이터가 잘 정렬되어 있음.
clustering_factor 수치가 테이블 블록에 가까울수록 데이터가 잘 정렬되어 있음.
- 물리적 I/O: CF가 좋은 인덱스라면 index-range scan 후 레코드도 가까운 시점에서 읽힐 가능성이 높다. 물리적인 I/O 횟수가 감소.
- 논리적 I/O: 버퍼 Pinning 효과에 의해 접근하는 논리적 block 수가 감소함.
- buffer Pinning: 방금 액세스한 버퍼에 대한 Pin을 즉각 해제하지 않고 데이터베이스 call 내에서 계속 유지하는 기능. 연속된 레코드가 같은 block을 가리키면 latch 획득 과정을 생략하기 때문에 logical read 수가 증가하지 않음.
인덱스 손익분기점
- buffer Pinning: 방금 액세스한 버퍼에 대한 Pin을 즉각 해제하지 않고 데이터베이스 call 내에서 계속 유지하는 기능. 연속된 레코드가 같은 block을 가리키면 latch 획득 과정을 생략하기 때문에 logical read 수가 증가하지 않음.
- index range scan에 의한 table access가 table full scan보다 느려지는 지점을 손익분기점이라 함.
- index rowid에 의한 테이블 액세스는 random인데, full table scan은 sequential 방식으로 이루어짐.
- 디스크 I/O시 index rowid는 single block read, full table scan은 multiblock read 방식.
- index를 사용한다고 언제나 좋은 효율을 내는 것은 아니다.
- 손익분기점을 극복하기 위한 방법들
- IOT
- 클러스터 테이블
- 파티셔닝
테이블 Random 액세스 최소화 튜닝
인덱스 컬럼추가
- 기존 인덱스에 컬럼을 추가하는 것만으로 효과를 볼 수도 있음
- 인덱스 스캔량은 줄지 않지만 테이블 random access 횟수를 줄이기 때문
PK인덱스에 컬럼추가
- 단일 테이블을 PK로 액세스 할 때는 단 한건만 조회, NL조인에서 Inner Table은 random access 부하가 많이 발생함.
- PK+필터조건을 포함한 새로운 non-unique index 추가해서 pk 제약 설정하면 인덱스 개수 줄일 수 있음.
alter table dept drop primary key; create index dept_x01 on dept (deptno, loc); alter table dept add constraint dept_pk primary key(deptno) using index dept_x01;컬럼 추가에 따른 클러스터링 팩터 변화
- 기존 인덱스에 컬럼을 추가했을 때 클러스터링 팩터가 나빠질 수 있음.
- object_type처럼 변별력이 좋지 않은 컬럼 뒤에 object_name처럼 변별력이 좋은 컬럼을 추가하면 rowid 이전에 object_name 순으로 정렬되기 때문.
인덱스만 읽고 처리
- table access가 발생하지 않도록 모든 필요한 컬럼을 인덱스에 포함시키는 방법
버퍼 Pinning 효과 활용
- 한번 입력된 레코드는 rowid가 바뀌지 않음.
- rowid를 이용한 레코드 조회가 가능. (where rowid = ~)
TABLE ACCESS (BY USER ROWID)- select from (select ~ order by rowid) 를 통해 테이블 액세스 가능.
수동으로 클러스터링 팩터 높히기
- 테이블에는 데이터가 무작위로 입력되고, 인덱스는 key순으로 정렬되므로 대게 CF가 좋지 않음.
- 인덱스를 기준으로 테이블을 재생성하여 인위적으로 CF를 좋게 만드는 방법
- 가장 자주 사용되는 인덱스를 기준, 다른 인덱스를 사용하는 쿼리에 영향을 주지 않는지 체크 필요
- 데이터 이관 과정에서도 CF가 나빠질 수 있다.
- 기존 입력 시에는 트랜잭션이 발생하는 순서대로 데이터 입력, 데이터를 이관할 때에는 병렬 쿼리를 이용해서 데이터를 흩어놓기 때문.
IOT, 클러스터 테이블 활용
IOT란?
create table t (a number primary key, b varchar(10)) organization index;
- 기존 입력 시에는 트랜잭션이 발생하는 순서대로 데이터 입력, 데이터를 이관할 때에는 병렬 쿼리를 이용해서 데이터를 흩어놓기 때문.
장점
- 정렬된 상태로 모여 있기 때문에 sequential 방식으로 액세스 가능. 넓은 범위를 액세스 할 때 유리
- FULL TABLE SCAN 시 자동적으로 ORDERING이 이루어짐.
- 인덱스 세그먼트를 생성하지 않아도 돼 저장공간 절약
단점
- PK로만 정렬이 가능. 추가적인 index 생성 불가능
- 데이터 입력시 성능이 느림
- 데이터 삽입시 인덱스 split 발생빈도가 높아지면 성능이 느려짐.
- IOT가 PK 이외에 많은 컬럼을 갖는다면 리프 블록에 저장해야 할 데이터가 늘어나 split 빈도도 높아짐.
- 클러스터링 테이블 불가
- 병렬 작업 불가
- 분산, 복제, 분할 불가
- LOB불가
IOT, 언제 사용할 것인가
- 크기가 작고 NL 조인으로 반복 Lookup 하는 테이블
- row 수가 많고, column 수가 적은 테이블
- 관계형 테이블(방문일시 등)에서 PK는 어짜피 생성해야 하므로, 테이블과 거의 중복된 데이터를 갖게 됨. 차라리 IOT로 구성하는 게 좋다.
- 넓은 범위를 주로 검색하는 테이블
- Between, Like처럼 넓은 범위를 검색하는 테이블 (통계성 테이블 등)
- 데이터 입력과 조회 패턴이 다른 테이블
- 등록은 일자별로, 조회는 번호별로
Partitioned IOT
- 데이터 수가 늘어나면 인덱스를 사용해도 부담스러움.
- 월별 파티셔닝 등
Overflow 영역
- PK 이외 컬럼이 많은 테이블이면 IOT로 구성하기 부적합. 하지만 이용하려면 분리 저장.
- 옵션
OVERFLOW TABLESPACE: Overflow 세그먼트가 저장될 테이블스페이스 지정PCTHRESHOLD: 이 값을 초과하면 뒤쪽 컬럼은 overflow 세그먼트에 저장INCLUDING: 여기에 지정된 컬럼까지만 인덱스 블록에 저장. 나머지는 overflow 영역에 저장.
- overflow 영역에도 버퍼 pinning 효과가 나타나기 때문에 연속적으로 같은 overflow 영역을 읽으면 random 블록 I/O 최소화
Secondary 인덱스
- IOT 레코드 위치는 영구적이지 않기 때문에 secondary 인덱스로부터 IOT 레코드를 가리킬 때 물리적 주소 대신 logical rowid 사용
- Logical Rowid = PK + physical guess
- physical guess란 인덱스를 생성한 시점에 IOT 레코드가 위치했던 DBA. 분할되면 갱신되지 않음.
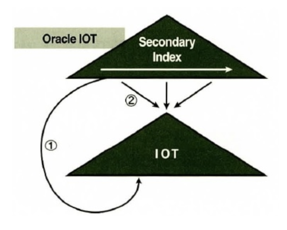 ①은 physical guess를 통해 레코드 직접 액세스
②는 PK를 통해 IOT 탐색
①은 physical guess를 통해 레코드 직접 액세스
②는 PK를 통해 IOT 탐색
PCT_DIRECT ACCESS: 유효한 physical guess를 가진 비율. 100% 미만이면 바로 PK를 이용해 IOT를 탐색. 재생성하면 100%- 비휘발성 IOT 인 경우 pct_direct_access 값을 100으로 유지.
- 읽기전용이라면 항상 100이겠지만, 우측에 지속적으로 값을 입력하는 경우에는 통계정보 수집이 필수.
- 휘발성 IOT 인 경우 주기적으로 physical guess를 갱신.
Right-Growing IOT에서 pct_direct_access가 100미만으로 떨어지는 이유
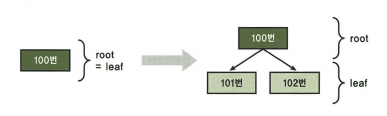
- 100번 블록이 꽉 차면 101번 블록에 모두 복제하고 100은 루트로 올라감. 새로 추가되는 값들은 102에 입력됨. (physical guess 오류)
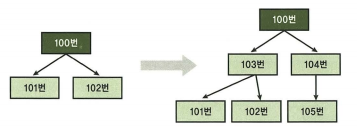
- 100번 정보를 103에게 넘겨줄 뿐, 다른 리프 블록에 변화가 없음.(physical guess 영향없음)
root block은 특별하기 때문에 항상 같은 block이도록 함.
인덱스 클러스터 테이블
- 클러스터 키 값이 같은 레코드가 한 블록에 모이도록 저장하는 구조
- 한 블록에 모두 담을 수 없을 때에는 새로운 블럭을 할당해 클러스터 체인으로 연결
- 이미 클러스터값의 기준으로 JOIN되어있는 구조
- 넓은 범위를 검색할 때 유리
- 클러스터 인덱스를 ‘=’ 조건으로 액세스 할 때는 항상 unique scan
- 성능 이슈
- DML 성능 떨어짐. (없던 값을 입력할 때에는 블록 새로 입력받아야 해서 더 느림)
- 전체 데이터 지울 때 Truncate 불가. (클러스터를 truncate해야 함)
- 다중 테이블 클러스터 fullscan시 다른 테이블 데이터까지 스캔
- SIZE 옵션
- 하나의 블록에 여러 클러스터 키가 담길 수 있게. SIZE는 하나의 블록에 담을 최대 클러스터 키 개수를 결정지음.
해시 클러스터 테이블
- 해시 함수가 인덱스 역할을 대신하는 것.
- ’=’ 검색만 가능
- 물리적 인덱스를 갖지 않기 때문에 블록 I/O가 덜 발생.
인덱스 스캔 효율
Sequential 액세스 선택도 높이고, Random 액세스 발생량 줄이기
비교 연산자 종류와 컬럼 순서에 따른 인덱스 레코드의 군집성
- 첫 번째 나타나는 범위검색 조건까지만 만족하는 인덱스 레코드는 모두 연속되게 모여 있지만, 그 이하 조건가지 만족하는 레코드는 비교 연산자 종류에 상관없이 흩어짐.
인덱스 선행 컬럼이 (=)가 아닐 때 발생하는 비효율
- 선두 컬럼이 적게 잡힐 수 있는 인덱스 구조를 채택해야 함.
Between 조건을 IN-List로 바꾸었을 때 인덱스 스캔 효율
- in-list 안에 있는 레코드만큼 수직적 탐색이 일어남.
INLIST ITERATOR-> union all과 같다.- In list 개수가 많고, 인덱스 높이가 높을 때 비효율이 크다.
Index Skip Scan을 이용한 비효율 해소
- 인덱스 선두 컬럼이 between이더라도 index skip scan으로 효율성을 높일 수 있음.

- index(판매월, 판매구분)
- where 판매월 between ‘200801’ and ‘200802’ and 판매구분=’A’
범위검색 조건을 남용할 때 발생하는 비효율
- ’=’검색으로 하면 짧게 검색할 상황에, like 연산자를 사용해서 조회 성능에 영향을 끼칠 수도 있다.
같은 컬럼에 두 개의 범위검색 조건 시 주의사항
- rowid를 conctenation하면 rowidtochar 함수를 통해 문자열로 변환되어서, rowid 그대로 비교할 때랑 정렬 순서가 다름.
- 인덱스를 스캔하면서 rowid를 필터링할 때에는 비효율 발생.
- 인덱스 rowid는 leaf 블록에만 있기 때문에 이를 필터링하려면 일단 다른 조건으로 leaf block을 찾아가야 함. 거기서 rowid를 필터링해야 함.
Between과 Like 스캔 범위 비교
결론: between이 like보다 더 넓은 범위를 스캔하는 경우는 없다.
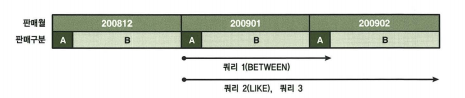 쿼리 1
쿼리 1
select * from 판매집계
where 판매월 between '200901' and '200902'
and 판매구분='A';
쿼리 2
select * from 판매집계
where 판매월 like '2009%'
and 판매구분='A';
쿼리 3
select count(*) from 판매집계
where 판매월>='200901'
and 판매월 < '200903'
and 판매구분='A';
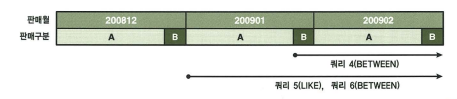 쿼리 4
쿼리 4
select * from 판매집계
where 판매월 between '200901' and '200912'
and 판매구분='B';
- 판매월=200901이고, 판매구분=B인 레코드를 목표로 수직적 탐색.
쿼리 5
select * from 판매집계 where 판매월 like '2009%' and 판매구분='B'; - 판매월=2009이고, 판매구분=B인 레코드를 목표로 수직적 탐색.
쿼리 6
select count(*) from 판매집계 where 판매월 between '200900' and '200902' and 판매구분='B';선분이력의 인덱스 스캔 효율
- 과거데이터 조회시 시작일 + 종료일 로 인덱스 구성
- 최근데이터 조회시 종료일 + 시작일 로 인덱스 구성
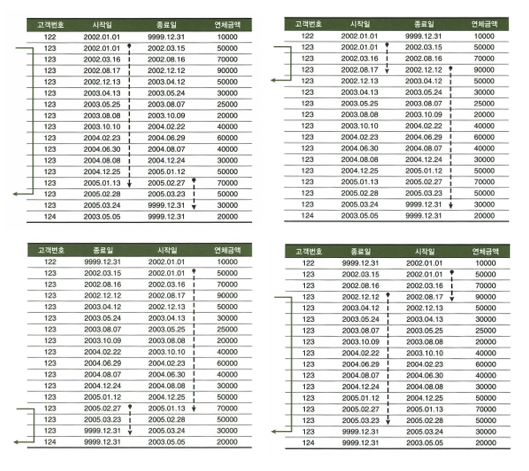
Access Predicate와 Filter Predicate
- 인덱스를 경유할 때에는
- 인덱스 단계에서의 access predicate
- 인덱스 단계에서의 filter predicate
- 테이블 단계에서의 filter predicate
- 인덱스를 경유하지 않을 때에는
- 테이블 단계에서의 filter predicate
- 인덱스 단계의 access predicate는 인덱스 스캔 범위를 결정하는 데에 영향을 미치는 조건절
- 아래 경우에는 인덱스 스캔 범위를 결정하는 데에 영향을 미치지 않으므로 access predicate에서 제외됨.
- 좌변 컬럼 가공
- 왼쪽, 양쪽 ‘%’ 사용하는 like 조건절
- 같은 컬럼 조건절이 두개 이상일 때, 인덱스를 타지 않는 조건절
- 이 경우를 제외하면 수직적 탐색 과정에서 모든 인덱스 컬럼을 비교 조건으로 사용
- 아래 경우에는 인덱스 스캔 범위를 결정하는 데에 영향을 미치지 않으므로 access predicate에서 제외됨.
- 인덱스 단계에서의 filter predicate는 테이블로의 액세스 여부를 결정짓는 조건절
- 테이블 단계에서의 filter predicate는 테이블을 액세스하고 나서 최종 결과집합으로 포함여부를 결정짓는 조건절
Index Fragmentation
- Index Skew: 인덱스 엔트리가 왼쪽, 오른쪽에 치우치는 현상. Index Full Scan시 성능이 나빠짐.
- Index Spare: skew처럼 블록이 비면 freelist로 반환되겠지만, spare는 반환되지 않고 남아있는 상태.
- Index Rebuild:
alter index t_idx coalesce;를 통해 여러 인덱스 블록을 merge하고, 남은 블록을 freelist에 반환.- 하지만 index block에는 어느정도 공간을 남겨두는 것이 좋다. 전혀 없으면 인덱스 분할이 일어나서 TX 이벤트 발생.
- index rebuild를 고려하면 좋을 경우
- 인덱스 분할에 의한 contention이 높을 때
- 자주 사용되는 인덱스 스캔 효율을 높일 때. 인덱스 height이 증가했을 때
- 대량의 delete 작업 후 다시 레코드 입력까지 오래걸릴 때
- 총 레코드 수가 일정한데도 인덱스가 계속 커질 때
인덱스 설계
필수 선택 기준
Index Range Scan을 고려해야 함.
- 조건절에 항상 사용되거나, 자주 사용되는 컬럼들을 선택
- ’=’조건으로 자주 조회되는 컬럼들을 앞쪽에 배치
결합 인덱스 컬럼 순서 결정
- 인덱스 생성 여부를 결정할 때, 선택도가 충분히 낮은지 확인. 선택도가 높은 인덱스는 효용가치가 없음.
- 선택도가 높다 = 변별력이 떨어진다
선택도가 액세스 효율에 영향을 주지 않는 경우
IDX01 : 고객등급 + 고객번호 + 거래일자 + 거래유형 + 상품번호
- 선택도가 높다 = 변별력이 떨어진다
- 고객등급, 고객번호는 ‘=’조건, 거래일자는 between 일 때 위와 같은 인덱스
- between인 거래일자 뒤의 거래유형, 상품번호는 어짜피 인덱스 필터 조건으로 사용되므로 변별력을 따질 필요가 없음.
- ’=’, ‘=’, ‘between’이므로 범위 검색조건 전까지 인덱스가 다 모여있음.
- 변별력이 좋지 않은 고객등급을 앞에 둬도 스캔 범위가 어짜피 최소화.
상황에 따라 유 · 불리가 바뀌는 경우
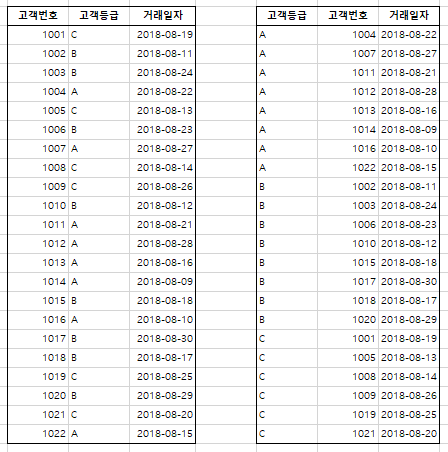
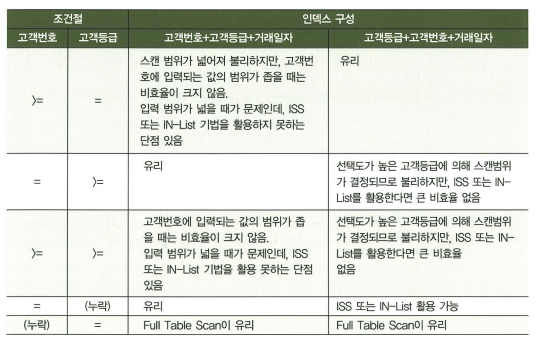
- 선택도가 높은 컬럼(고객등급)을 선두에 두면 누락되거나, 범위검색 조건에 사용되더라도 Index Skip Scan이나 IN-List를 활용할 수 있어서 유리.
- 선택도가 낮은 컬럼을 선두에 두면 범위검색일 때 불리하지만, 입력 값의 범위가 좁다면 유리.
Sort 생략을 위한 컬럼 추가
- 인덱스를 이용해 소트 연산을 대체하려면 인덱스 컬럼 순서와 같은 순서로 누락 없이 order by에 기술해야 함.
비트맵 인덱스
비트맵 인덱스 기본 구조
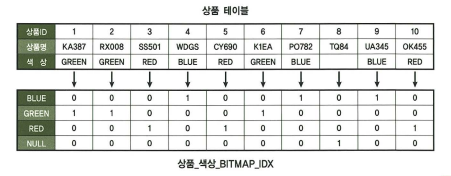
- 키 값별로 하나의 비트맵 레코드를 갖음. 비트맵 상의 각 비트가 하나의 테이블 레코드와 매핑됨.
- 키 값의 수가 많으면 B*Index 구조를 띄게 되고, 일반적인 인덱스보다 더 많은 공간을 차지할 수 있어 부적합.
- 비트맵 압축: 압축으로 인해 시작 rowid와 종료 rowid가 달라질 수 있음. checksum을 이용한 압축도 가능. 시작과 종료 rowid만 알고 있으면 bitwise 연산에는 문제가 없음.
비트맵 인덱스 활용
- distinct value가 적을 때(성별) 효율이 좋다.
- 하나의 비트맵 인덱스보다, 여러 비트맵 인덱스를 동시에 사용할 수 있을 때 효율이 크다.
Subscribe via RSS